Accessing Data with API’s#
OBJECTIVES
More with
groupbyand.aggData Access via API
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
Data Input via APIs#
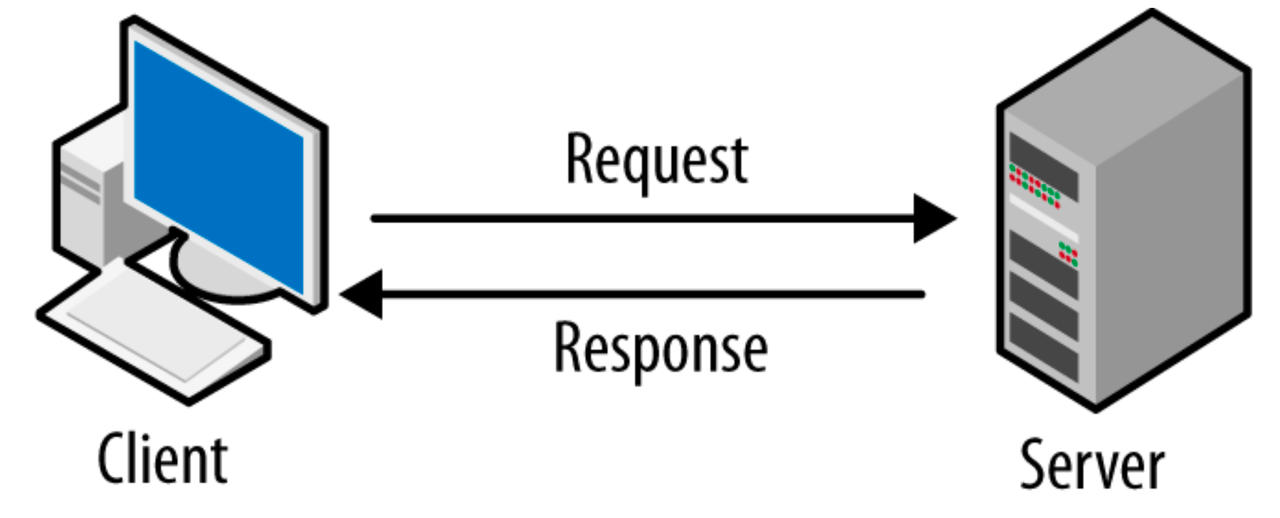
This is about using an api “Application program interface” …basic idea, allows direct access to some database or parts of it without having do download everything
import os
import pandas as pd
import matplotlib.pyplot as plt
import datetime
Accessing Data Without a Library#

To start, we will use the federal reserve of St. Louis API as a running example. Head over here to view the documentation.
Exploring the data releases#
As a first example, we will make a request of the api and try to structure the response as a DataFrame.
import requests
api_key = 'aec8814bc2a87a3f6caaf615d0529cf0'
#url from api docs
url = f'https://api.stlouisfed.org/fred/releases?api_key={api_key}&file_type=json'
#make a request
response = requests.get(url)
#examine response code
response
<Response [200]>
#text of the response
response.text[:1000]
'{"realtime_start":"2025-09-29","realtime_end":"2025-09-29","order_by":"release_id","sort_order":"asc","count":319,"offset":0,"limit":1000,"releases":[{"id":9,"realtime_start":"2025-09-29","realtime_end":"2025-09-29","name":"Advance Monthly Sales for Retail and Food Services","press_release":true,"link":"http:\\/\\/www.census.gov\\/retail\\/","notes":"The U.S. Census Bureau conducts the Advance Monthly Retail Trade and Food Services Survey to provide an early estimate of monthly sales by kind of business for retail and food service firms located in the United States. Each month, questionnaires are mailed to a probability sample of approximately 4,700 employer firms selected from the larger Monthly Retail Trade Survey. Advance sales estimates are computed using a link relative estimator. For each detailed industry, we compute a ratio of current-to previous month weighted sales using data from units for which we have obtained usable responses for both the current and previous month. For each '
#turn into json
data = response.json()
#DataFrame of response
pd.DataFrame(data['releases']).head()
| id | realtime_start | realtime_end | name | press_release | link | notes | |
|---|---|---|---|---|---|---|---|
| 0 | 9 | 2025-09-29 | 2025-09-29 | Advance Monthly Sales for Retail and Food Serv... | True | http://www.census.gov/retail/ | The U.S. Census Bureau conducts the Advance Mo... |
| 1 | 10 | 2025-09-29 | 2025-09-29 | Consumer Price Index | True | http://www.bls.gov/cpi/ | NaN |
| 2 | 11 | 2025-09-29 | 2025-09-29 | Employment Cost Index | True | http://www.bls.gov/ncs/ect | NaN |
| 3 | 13 | 2025-09-29 | 2025-09-29 | G.17 Industrial Production and Capacity Utiliz... | True | http://www.federalreserve.gov/releases/g17/ | For questions on the data, please contact the ... |
| 4 | 14 | 2025-09-29 | 2025-09-29 | G.19 Consumer Credit | True | http://www.federalreserve.gov/releases/g19/ | For questions on the data, please contact the ... |
Finding Series#
From the search documentation here.
url = f'https://api.stlouisfed.org/fred/series/search?search_text=consumer+price+index&api_key={api_key}&file_type=json'
#make request turn into json
r = requests.get(url)
data = r.json()
#explore the keys of response
#dataframe of seriess
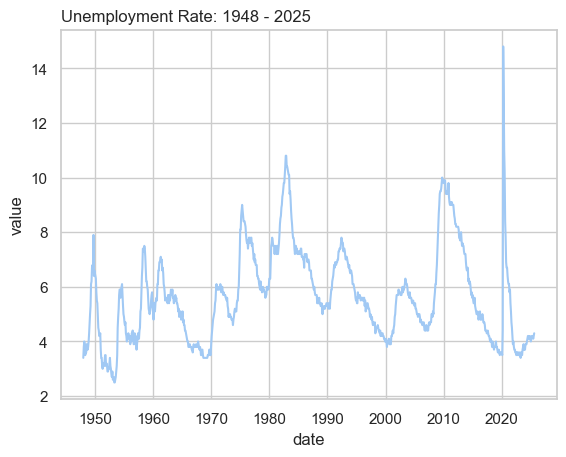
Exploring the Unemployment Rate#
The unemployment rate is series_id: 'UNRATE'. We explore the data below.
url = 'https://api.stlouisfed.org/fred/series/observations'
#structure url and make request
params = {'series_id':'UNRATE',
'api_key': api_key,
'file_type': 'json'}
r = requests.get(url, params = params)
#response code
<Response [200]>
#explore the text
'{"realtime_start":"2025-09-29","realtime_end":"2025-09-29","order_by":"search_rank","sort_order":"desc","count":30392,"offset":0,"limit":1000,"seriess":[{"id":"CPIAUCSL","realtime_start":"2025-09-29",'
#turn into json
#observations are what we want
#dataframe of observations
obs_df = ''
#look over .info
#change value to float
#change date to datetime
#set date to index
sns.set_theme(style="whitegrid", palette="pastel")
sns.lineplot(data = obs_df,x = obs_df.index, y = 'value')
plt.title('Unemployment Rate: 1948 - 2025', loc = 'left');
!pip install fredpy
Collecting fredpy
Using cached fredpy-3.2.10-py3-none-any.whl.metadata (442 bytes)
Using cached fredpy-3.2.10-py3-none-any.whl (11 kB)
Installing collected packages: fredpy
Successfully installed fredpy-3.2.10
[notice] A new release of pip is available: 24.3.1 -> 25.2
[notice] To update, run: pip install --upgrade pip
PROBLEM
Find another series from the FRED data and create a plot of your response.
Accessing Data with a Library#
The SEC shares much of its data through an API called EDGAR. There is a library pyedgar that allows you to interact with the API here. Can you use the library to extract filings for a company of your choosing?
!pip install edgar
Collecting edgar
Downloading edgar-5.6.3-py3-none-any.whl.metadata (6.9 kB)
Requirement already satisfied: requests in /Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/site-packages (from edgar) (2.32.3)
Requirement already satisfied: lxml in /Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/site-packages (from edgar) (5.1.0)
Requirement already satisfied: tqdm in /Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/site-packages (from edgar) (4.67.1)
Collecting rapidfuzz (from edgar)
Downloading rapidfuzz-3.14.1-cp312-cp312-macosx_10_13_x86_64.whl.metadata (12 kB)
Requirement already satisfied: charset-normalizer<4,>=2 in /Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/site-packages (from requests->edgar) (3.3.2)
Requirement already satisfied: idna<4,>=2.5 in /Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/site-packages (from requests->edgar) (3.6)
Requirement already satisfied: urllib3<3,>=1.21.1 in /Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/site-packages (from requests->edgar) (2.1.0)
Requirement already satisfied: certifi>=2017.4.17 in /Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/site-packages (from requests->edgar) (2024.8.30)
Downloading edgar-5.6.3-py3-none-any.whl (23 kB)
Downloading rapidfuzz-3.14.1-cp312-cp312-macosx_10_13_x86_64.whl (1.9 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.9/1.9 MB 3.5 MB/s eta 0:00:00a 0:00:01
?25hInstalling collected packages: rapidfuzz, edgar
Successfully installed edgar-5.6.3 rapidfuzz-3.14.1
[notice] A new release of pip is available: 24.3.1 -> 25.2
[notice] To update, run: pip install --upgrade pip
from edgar import Company, TXTML
company = Company("INTERNATIONAL BUSINESS MACHINES CORP", "0000051143")
doc = company.get_10K()
text = TXTML.parse_full_10K(doc)
print(text[:1000])
version='1.0' encoding='ASCII'? XBRL Document Created with the Workiva Platform Copyright 2025 Workiva r:e5e4c6dd-a0e3-4a8d-aa78-eb8c6666d274,g:21436d97-1a01-444f-9a49-04dee52d2242,d:af7e987c179946fe9556e9c6006b4d87 ibm-20241231 CHX 0000051143 2024 FY false P5Y P3Y http://fasb.org/us-gaap/2024#Revenues http://fasb.org/us-gaap/2024#Revenues http://fasb.org/us-gaap/2024#Revenues P1Y P1Y http://fasb.org/us-gaap/2024#SellingGeneralAndAdministrativeExpense http://fasb.org/us-gaap/2024#SellingGeneralAndAdministrativeExpense http://fasb.org/us-gaap/2024#SellingGeneralAndAdministrativeExpense P1Y P1Y http://fasb.org/us-gaap/2024#AccountsPayableCurrent http://fasb.org/us-gaap/2024#AccountsPayableCurrent http://fasb.org/us-gaap/2024#PropertyPlantAndEquipmentAndFinanceLeaseRightOfUseAssetAfterAccumulatedDepreciationAndAmortization http://fasb.org/us-gaap/2024#PropertyPlantAndEquipmentAndFinanceLeaseRightOfUseAssetAfterAccumulatedDepreciationAndAmortization http://fasb.org/us-gaap/2024#ShortTermB
Last FM#
The API for Last FM requires an API Key. Head over here to signup for yours – it should be instantaneous.
base_url = ''
#examine the response
#extract the headline
Exercise
Use the album.GetInfo method docs to get information about an album of your choosing.
Finding an API#
There are many different API’s with interesting data out there. Your goal is to find an API of interest and make a request of the API, structuring the result as a DataFrame. Record your findings here.