Probability Distributions: Discrete and Continuous#
OBJECTIVES
Model with discrete probability distributions
Use
scipy.statsto create discrete distributionsUse
.pdf, .cdfmethods of distributions
Widgets#
In a terminal please run the following
conda install -c conda-forge nodejs
jupyter labextension install @jupyter-widgets/jupyterlab-manager
Restart your JupyterLab instance and run the cell below.
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import scipy.stats as stats
import seaborn as sns
from ipywidgets import interact
import ipywidgets as widgets
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
Cell In[1], line 5
3 import pandas as pd
4 import scipy.stats as stats
----> 5 import seaborn as sns
7 from ipywidgets import interact
8 import ipywidgets as widgets
ModuleNotFoundError: No module named 'seaborn'
Descriptive Statistics Review#
REVIEW
Write a function that takes in a list and returns the arithmetic mean of that list. (no numpy!)
#function for mean
def arithmetic_mean(x):
return sum(x)/len(x)
list_1 = [5, 5, 5, 5, 5]
list_2 = [3, 4, 5, 6, 7]
list_3 = [1, 3, 5, 7, 9]
#list comprehension to apply your function
[arithmetic_mean(i) for i in (list_1, list_2, list_3)]
[5.0, 5.0, 5.0]
Variance#
IN WORDS:
IN SYMBOLS: $\(\frac{1}{n}\sum_{i = 1}^{n} (x_i - \mu)^2\)$
list_1
[5, 5, 5, 5, 5]
#mean of list 1
l1_mean = 5
#variance of list 1
sum([(xi - l1_mean)**2 for xi in list_1])/len(list_1)
0.0
#function for variance
def variance(x):
x_mean = arithmetic_mean(x)
return sum([(xi - x_mean)**2 for xi in x])/len(x)
#find the variance of our lists above
[variance(l) for l in (list_1, list_2, list_3)]
[0.0, 2.0, 8.0]
#interpret these values
Standard Deviation#
The square root of the variance – puts things back in terms of the original unit.
#function for square root
def sqrt(x):
return x**.5
#evaluate on our lists
[sqrt(variance(l)) for l in (list_1, list_2, list_3)]
[0.0, 1.4142135623730951, 2.8284271247461903]
PROBLEMS
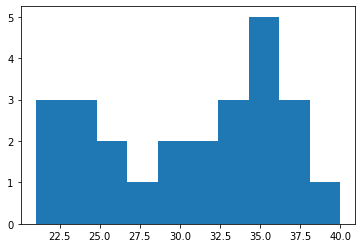
Use the list of player ages below to compute the mean and standard deviation of the data.
Determine the age range within 1.5 standard deviation of the mean.
player_ages = [21, 21, 22, 23, 24, 24, 25, 25, 28, 29, 29, 31, 32, 33, 33, 34, 35, 36, 36, 36, 36, 38, 38, 38, 40]
np.mean(player_ages), np.std(player_ages)
(30.68, 5.9713984961648645)
# lower, upper
np.mean(player_ages) - 1.5*np.std(player_ages), np.mean(player_ages) + 1.5*np.std(player_ages)
(21.722902255752704, 39.6370977442473)
plt.hist(player_ages)
(array([3., 3., 2., 1., 2., 2., 3., 5., 3., 1.]),
array([21. , 22.9, 24.8, 26.7, 28.6, 30.5, 32.4, 34.3, 36.2, 38.1, 40. ]),
<BarContainer object of 10 artists>)
Probability Mass Functions#
We will care about matching the right probability distribution with a given scenario. Today we introduce some primary distributions with discrete and continuous value inputs.
Example I: Bernoulli Trial#
One event with a binary outcome and a probability of success (and failure).
outcome |
probability |
|---|---|
Heads |
0.3. |
Tails |
0.7 |
import scipy.stats as stats
#distribution to model
coin_flip = stats.bernoulli(p = .3)
#probability of failure
coin_flip.pmf(0)
0.7
#probability of success
coin_flip.pmf(1)
0.3
#variance of the trial
coin_flip.var()
0.21
#standard deviation of the trial
coin_flip.std()
0.458257569495584
# #plot
x = np.arange(2)
plt.plot(x, coin_flip.pmf(x), 'o')
plt.vlines(0, 0, .7)
plt.vlines(1, 0, .3)
<matplotlib.collections.LineCollection at 0x7fc9dc7a64c0>

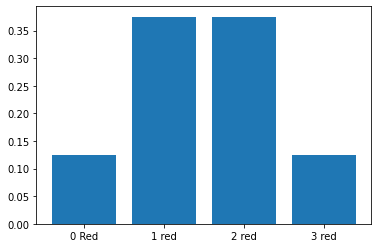
An Old Game: Sennet#
We have some number of popsicle sticks colored blue or red on different sides. We drop them and explore the possible outcomes. Imagining each outcome is equally likely, please determine the following:
Drop 1 stick, \(P(R)\)
Drop 1 stick, \(P(B)\)
Drop 2 sticks, what are all possible outcomes? \(P(\text{one red one blue})\)?
Drop 3 sticks, what are all the possible outcomes? \(P(\text{BBB})\)?
#define combinations
#from 3 sticks, how many ways are there
#to land all blue
from scipy.special import comb
#from 3 sticks how many ways are there for 3 "successes"
comb(3, 3)
1.0
#examine outcomes for 3 coins
[comb(3, i) for i in range(4)]
[1.0, 3.0, 3.0, 1.0]
#determine probabilities for each
[comb(3, i)/2**3 for i in range(4)]
[0.125, 0.375, 0.375, 0.125]
#make a bar plot of probabilities
plt.bar([0, 1, 2, 3], [comb(3, i)/2**3 for i in range(4)])
plt.xticks([0, 1, 2, 3], ['0 Red', '1 red', '2 red', '3 red']);
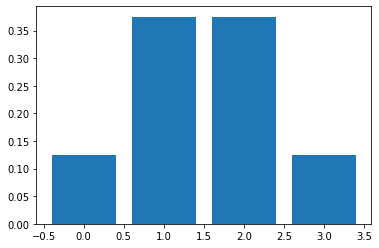
Binomial Distribution#
Used to model repeated Bernoulli trials. For example, toss a coin four times. Its probability mass function is given by:
#define binomial
coin_flip = stats.binom(n = 3, p = 0.5)
#probability of 2 heads
coin_flip.pmf(2)
0.3750000000000001
#probability of 3 heads
coin_flip.pmf(3)
0.125
#define range of all possible outcomes
x = np.arange(0, 4)
x
array([0, 1, 2, 3])
coin_flip.pmf(x)
array([0.125, 0.375, 0.375, 0.125])
#plot pmf
plt.bar(x, coin_flip.pmf(x));
#probability of no more than 2 heads
###p(0)
p0 = coin_flip.pmf(0)
###p(1)
p1 = coin_flip.pmf(1)
###p(2)
p2 = coin_flip.pmf(2)
p0 + p1 + p2
0.8750000000000002
Cumulative Distribution Function#
Evaluates the cumulative probability up to a given value. Formally it would be the sum or integral of probabilities until some value \(x_i\).
###Cumulative distribution function
coin_flip.cdf(2)
0.875
###plot side by side pmf and cdf
fig, ax = plt.subplots(nrows = 1, ncols = 2, figsize = (15, 4))
x = np.arange(0, 4)
ax[0].bar(x, coin_flip.pmf(x))
ax[0].set_title('PMF')
ax[1].plot(x, coin_flip.cdf(x))
ax[1].set_title('CDF')
ax[1].set_ylim(0, 1)
(0.0, 1.0)
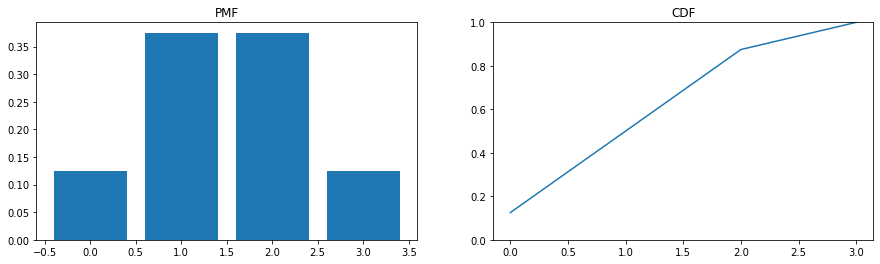
PROBLEMS
Here are some good old fashioned math problems. Use our scipy distributions to solve each below. For extra bonus, add a plot and highlight the area or areas of interest.
A trainer is teaching a student to do tricks. The probability that the student successfully performs the trick is 35%, and the probability that the student does not successfully perform the trick is 65%. Out of 20 attempts, you want to find the probability that the student succeeds 12 times.
A fair, six-sided die is rolled ten times. Each roll is independent. You want to find the probability of rolling a one more than three times.
Approximately 70% of statistics students do their homework in time for it to be collected and graded. Each student does homework independently. In a statistics class of 50 students, what is the probability that at least 40 will do their homework on time?
p1 = stats.binom(n = 20, p = .35)
p1.pmf(12)
0.013564085376714436
p2 = stats.binom(n = 10, p = 1/6)
1 - p2.cdf(3)
0.0697278425544886
p3 = stats.binom(n = 50, p = .7)
1 - p3.cdf(39)
0.07885062482305638
Continuous Distributions#
Now, rather than discussing discrete distributions the topic shifts to distributions of continuous random variables. This simply means the objects we are working with are on continuous scales – weight, height, speed, etc.
Uniform Distribution#
The distribution describes an experiment where there is an arbitrary outcome that lies between certain bounds – Wikipedia
#define the uniform distribution
uniform_dist = stats.uniform(loc = 2, scale = 3)
#define a domain of values
x = np.linspace(0, 7, 1000)
#look at a plot of pdf
plt.plot(x, uniform_dist.pdf(x))
[<matplotlib.lines.Line2D at 0x7fc9db9c1250>]
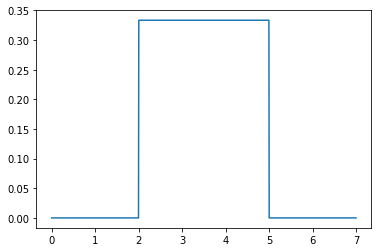
#probability of 3?
uniform_dist.pdf(3)
0.3333333333333333
#probabiity of 4 or fewer?
uniform_dist.cdf(4)
0.6666666666666666
#side by side plot of pdf and cdf
fig, ax = plt.subplots(1, 2, figsize = (16, 6))
ax[0].plot(x, uniform_dist.pdf(x))
ax[0].set_title('Uniform Distribution pdf')
ax[0].grid()
ax[1].plot(x, uniform_dist.cdf(x))
ax[1].set_title('Uniform Distribution cdf')
ax[1].grid()
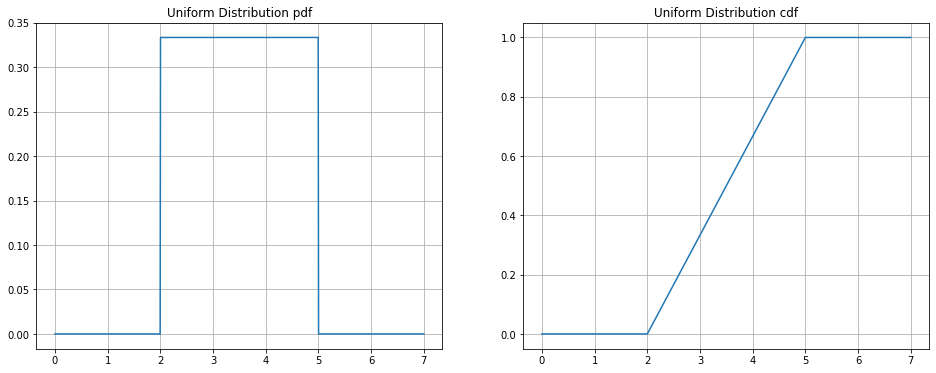
The Normal Distribution#
Normal distributions are important in statistics and are often used in the natural and social sciences to represent real-valued random variables whose distributions are not known. – Wikipedia
#mean of 100 sd of 3
norm_1 = stats.norm(loc = 100, scale = 3)
#plot pdf
x = np.linspace(88, 112, 1000)
plt.plot(x, norm_1.pdf(x))
plt.title('Normal Distribution pdf')
plt.xlabel('outcome')
plt.ylabel('probability')
plt.grid();
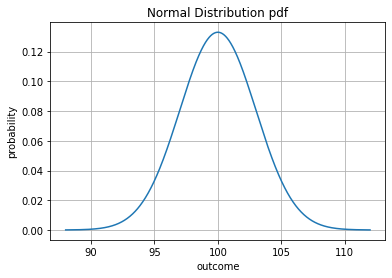
#how much between 97 and 103 -- one standard deviation?
norm_1.cdf(103) - norm_1.cdf(97)
0.6826894921370859
#how much data between 94 and 106?
norm_1.cdf(106) - norm_1.cdf(94)
0.9544997361036416
#between 91 and 109?
norm_1.cdf(109) - norm_1.cdf(91)
0.9973002039367398
GENERAL RULE: 68 - 95 - 99 rule.
Within 1, 2, and 3 standard deviations from the mean we have 68%, 95%, and 99% of our data with any normal distribution.
Parameters of Normal#
import ipywidgets as widgets
from ipywidgets import interact
def plot_pdt(mean_num, std_num):
norm_1 = stats.norm(loc = mean_num, scale = std_num)
x = np.linspace(mean_num - std_num * 4, mean_num + std_num * 4, 1000)
plt.plot(x, norm_1.pdf(x))
plt.xlim(80, 120)
plt.show();
#interact with it
interact(plot_pdt, mean_num = widgets.FloatSlider(min = 50, max = 150, step = 1, description = 'Mean'),
std_num = widgets.FloatSlider(min = 0.1, max = 20, step = 0.1, description = 'σ'))
<function __main__.plot_pdt(mean_num, std_num)>
PROBLEMS
The final exam scores in a statistics class were normally distributed with a mean of 63 and a standard deviation of five.
Find the probability that a randomly selected student scored more than 65 on the exam.
Find the probability that a randomly selected student scored less than 85.
The National Assessment of Educational Progress is a test that examines student performance in most states. The NAEP reading scores assume a normal distribution \(N(288, 38)\). What range of scores encompasses 95% of the student data?
p1 = stats.norm(loc = 63, scale = 5)
1 - p1.cdf(65)
0.3445782583896758
p1.cdf(85)
0.9999945874560923
p2 = ''
288 - 2*38, 288 + 2*38
(212, 364)