Model Complexity and Evaluation#
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
Polynomial Models#
Thus far, our regression models have taken the form:
where all our inputs to the model were linear.
In this notebook, we consider models of the form:
These are commonly referred to as Polynomial Regression Models – however we are still using Linear Regression because the unknown quantities – \(\beta\) – are linear.
#load in the cars data
cars = pd.read_csv('https://raw.githubusercontent.com/jfkoehler/nyu_bootcamp_fa24/main/data/mtcars.csv')
---------------------------------------------------------------------------
SSLCertVerificationError Traceback (most recent call last)
File /Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/urllib/request.py:1344, in AbstractHTTPHandler.do_open(self, http_class, req, **http_conn_args)
1343 try:
-> 1344 h.request(req.get_method(), req.selector, req.data, headers,
1345 encode_chunked=req.has_header('Transfer-encoding'))
1346 except OSError as err: # timeout error
File /Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/http/client.py:1319, in HTTPConnection.request(self, method, url, body, headers, encode_chunked)
1318 """Send a complete request to the server."""
-> 1319 self._send_request(method, url, body, headers, encode_chunked)
File /Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/http/client.py:1365, in HTTPConnection._send_request(self, method, url, body, headers, encode_chunked)
1364 body = _encode(body, 'body')
-> 1365 self.endheaders(body, encode_chunked=encode_chunked)
File /Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/http/client.py:1314, in HTTPConnection.endheaders(self, message_body, encode_chunked)
1313 raise CannotSendHeader()
-> 1314 self._send_output(message_body, encode_chunked=encode_chunked)
File /Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/http/client.py:1074, in HTTPConnection._send_output(self, message_body, encode_chunked)
1073 del self._buffer[:]
-> 1074 self.send(msg)
1076 if message_body is not None:
1077
1078 # create a consistent interface to message_body
File /Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/http/client.py:1018, in HTTPConnection.send(self, data)
1017 if self.auto_open:
-> 1018 self.connect()
1019 else:
File /Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/http/client.py:1460, in HTTPSConnection.connect(self)
1458 server_hostname = self.host
-> 1460 self.sock = self._context.wrap_socket(self.sock,
1461 server_hostname=server_hostname)
File /Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/ssl.py:455, in SSLContext.wrap_socket(self, sock, server_side, do_handshake_on_connect, suppress_ragged_eofs, server_hostname, session)
449 def wrap_socket(self, sock, server_side=False,
450 do_handshake_on_connect=True,
451 suppress_ragged_eofs=True,
452 server_hostname=None, session=None):
453 # SSLSocket class handles server_hostname encoding before it calls
454 # ctx._wrap_socket()
--> 455 return self.sslsocket_class._create(
456 sock=sock,
457 server_side=server_side,
458 do_handshake_on_connect=do_handshake_on_connect,
459 suppress_ragged_eofs=suppress_ragged_eofs,
460 server_hostname=server_hostname,
461 context=self,
462 session=session
463 )
File /Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/ssl.py:1046, in SSLSocket._create(cls, sock, server_side, do_handshake_on_connect, suppress_ragged_eofs, server_hostname, context, session)
1045 raise ValueError("do_handshake_on_connect should not be specified for non-blocking sockets")
-> 1046 self.do_handshake()
1047 except (OSError, ValueError):
File /Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/ssl.py:1317, in SSLSocket.do_handshake(self, block)
1316 self.settimeout(None)
-> 1317 self._sslobj.do_handshake()
1318 finally:
SSLCertVerificationError: [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1000)
During handling of the above exception, another exception occurred:
URLError Traceback (most recent call last)
Cell In[2], line 2
1 #load in the cars data
----> 2 cars = pd.read_csv('https://raw.githubusercontent.com/jfkoehler/nyu_bootcamp_fa24/main/data/mtcars.csv')
File /Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/site-packages/pandas/io/parsers/readers.py:1026, in read_csv(filepath_or_buffer, sep, delimiter, header, names, index_col, usecols, dtype, engine, converters, true_values, false_values, skipinitialspace, skiprows, skipfooter, nrows, na_values, keep_default_na, na_filter, verbose, skip_blank_lines, parse_dates, infer_datetime_format, keep_date_col, date_parser, date_format, dayfirst, cache_dates, iterator, chunksize, compression, thousands, decimal, lineterminator, quotechar, quoting, doublequote, escapechar, comment, encoding, encoding_errors, dialect, on_bad_lines, delim_whitespace, low_memory, memory_map, float_precision, storage_options, dtype_backend)
1013 kwds_defaults = _refine_defaults_read(
1014 dialect,
1015 delimiter,
(...)
1022 dtype_backend=dtype_backend,
1023 )
1024 kwds.update(kwds_defaults)
-> 1026 return _read(filepath_or_buffer, kwds)
File /Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/site-packages/pandas/io/parsers/readers.py:620, in _read(filepath_or_buffer, kwds)
617 _validate_names(kwds.get("names", None))
619 # Create the parser.
--> 620 parser = TextFileReader(filepath_or_buffer, **kwds)
622 if chunksize or iterator:
623 return parser
File /Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/site-packages/pandas/io/parsers/readers.py:1620, in TextFileReader.__init__(self, f, engine, **kwds)
1617 self.options["has_index_names"] = kwds["has_index_names"]
1619 self.handles: IOHandles | None = None
-> 1620 self._engine = self._make_engine(f, self.engine)
File /Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/site-packages/pandas/io/parsers/readers.py:1880, in TextFileReader._make_engine(self, f, engine)
1878 if "b" not in mode:
1879 mode += "b"
-> 1880 self.handles = get_handle(
1881 f,
1882 mode,
1883 encoding=self.options.get("encoding", None),
1884 compression=self.options.get("compression", None),
1885 memory_map=self.options.get("memory_map", False),
1886 is_text=is_text,
1887 errors=self.options.get("encoding_errors", "strict"),
1888 storage_options=self.options.get("storage_options", None),
1889 )
1890 assert self.handles is not None
1891 f = self.handles.handle
File /Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/site-packages/pandas/io/common.py:728, in get_handle(path_or_buf, mode, encoding, compression, memory_map, is_text, errors, storage_options)
725 codecs.lookup_error(errors)
727 # open URLs
--> 728 ioargs = _get_filepath_or_buffer(
729 path_or_buf,
730 encoding=encoding,
731 compression=compression,
732 mode=mode,
733 storage_options=storage_options,
734 )
736 handle = ioargs.filepath_or_buffer
737 handles: list[BaseBuffer]
File /Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/site-packages/pandas/io/common.py:384, in _get_filepath_or_buffer(filepath_or_buffer, encoding, compression, mode, storage_options)
382 # assuming storage_options is to be interpreted as headers
383 req_info = urllib.request.Request(filepath_or_buffer, headers=storage_options)
--> 384 with urlopen(req_info) as req:
385 content_encoding = req.headers.get("Content-Encoding", None)
386 if content_encoding == "gzip":
387 # Override compression based on Content-Encoding header
File /Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/site-packages/pandas/io/common.py:289, in urlopen(*args, **kwargs)
283 """
284 Lazy-import wrapper for stdlib urlopen, as that imports a big chunk of
285 the stdlib.
286 """
287 import urllib.request
--> 289 return urllib.request.urlopen(*args, **kwargs)
File /Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/urllib/request.py:215, in urlopen(url, data, timeout, cafile, capath, cadefault, context)
213 else:
214 opener = _opener
--> 215 return opener.open(url, data, timeout)
File /Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/urllib/request.py:515, in OpenerDirector.open(self, fullurl, data, timeout)
512 req = meth(req)
514 sys.audit('urllib.Request', req.full_url, req.data, req.headers, req.get_method())
--> 515 response = self._open(req, data)
517 # post-process response
518 meth_name = protocol+"_response"
File /Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/urllib/request.py:532, in OpenerDirector._open(self, req, data)
529 return result
531 protocol = req.type
--> 532 result = self._call_chain(self.handle_open, protocol, protocol +
533 '_open', req)
534 if result:
535 return result
File /Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/urllib/request.py:492, in OpenerDirector._call_chain(self, chain, kind, meth_name, *args)
490 for handler in handlers:
491 func = getattr(handler, meth_name)
--> 492 result = func(*args)
493 if result is not None:
494 return result
File /Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/urllib/request.py:1392, in HTTPSHandler.https_open(self, req)
1391 def https_open(self, req):
-> 1392 return self.do_open(http.client.HTTPSConnection, req,
1393 context=self._context)
File /Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/urllib/request.py:1347, in AbstractHTTPHandler.do_open(self, http_class, req, **http_conn_args)
1344 h.request(req.get_method(), req.selector, req.data, headers,
1345 encode_chunked=req.has_header('Transfer-encoding'))
1346 except OSError as err: # timeout error
-> 1347 raise URLError(err)
1348 r = h.getresponse()
1349 except:
URLError: <urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1000)>
cars.head(2)
| Unnamed: 0 | mpg | cyl | disp | hp | drat | wt | qsec | vs | am | gear | carb | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Mazda RX4 | 21.0 | 6 | 160.0 | 110 | 3.9 | 2.620 | 16.46 | 0 | 1 | 4 | 4 |
| 1 | Mazda RX4 Wag | 21.0 | 6 | 160.0 | 110 | 3.9 | 2.875 | 17.02 | 0 | 1 | 4 | 4 |
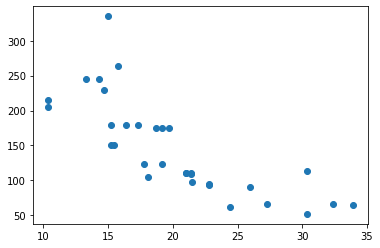
#x = mpg and y = hp
X = cars[['mpg']]
y = cars['hp']
#scatter plot of x vs. y
plt.scatter(X, y)
<matplotlib.collections.PathCollection at 0x7fba979fe130>
Reminder on Least Squares#
Assumptions of the model
The relationship between features and target are linear in nature
The features are independent of one another
The errors are normally distributed
The residuals have constant variance across all feature values
#fit model
lr = LinearRegression()
lr.fit(X, y)
preds = lr.predict(X)
#plot residuals
resids = (y - preds)
fig, ax = plt.subplots(1, 3, figsize = (20, 3))
ax[0].plot(resids, 'o')
ax[0].axhline(color = 'black')
ax[1].hist(resids)
ax[2].scatter(X['mpg'], y)
ax[2].plot(X['mpg'], lr.predict(X))
[<matplotlib.lines.Line2D at 0x7fba97ef1cd0>]

#Any assumptions violated? Why?
Reminder: Quadratics#
In plain language, we add a new feature to represent the quadratic term and fit a linear regressor to these columns, essentially what we’ve done with multiple regression.
#examine X
X.head()
| mpg | |
|---|---|
| 0 | 21.0 |
| 1 | 21.0 |
| 2 | 22.8 |
| 3 | 21.4 |
| 4 | 18.7 |
#add new feature
X['mpg^2'] = X['mpg']**2
<ipython-input-32-6eb7e30e5d7f>:2: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
X['mpg^2'] = X['mpg']**2
# check X again
X.head(2)
| mpg | mpg^2 | |
|---|---|---|
| 0 | 21.0 | 441.0 |
| 1 | 21.0 | 441.0 |
#fit model and look at coefficients
model1 = LinearRegression().fit(X, y)
model1.coef_
array([-23.34451763, 0.33002884])
# intercept
model1.intercept_
470.86947158376057
plt.scatter(X['mpg'], y)
plt.scatter(X['mpg'], model1.predict(X))
<matplotlib.collections.PathCollection at 0x7fba980ec250>
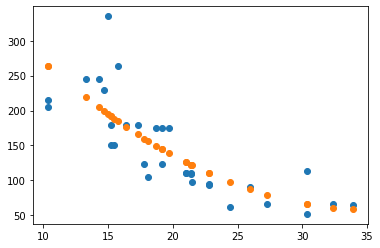
# mean squared error?
mean_squared_error(y, model1.predict(X))
1623.1102840474189
QUESTION: Which is better – the first or second degree model?
Problem#
Add a cubic term to the data.
Fit a new model to the cubic data.
Determine the
mean_squared_errorof the linear, quadratic, and cubic models. How do they compare?Would a quartic polynomial (4th degree) be better or worse in terms of
mean_squared_error?
X.loc[:, 'mpg^3'] = X['mpg']**3
lr3 = LinearRegression().fit(X, y)
print(f'MSE for degree 3: {mean_squared_error(y, lr3.predict(X))}')
MSE for degree 3: 1423.58061688618
<ipython-input-38-08c592816a90>:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
X.loc[:, 'mpg^3'] = X['mpg']**3
X.loc[:, 'mpg^4'] = X['mpg']**4
lr4 = LinearRegression().fit(X, y)
print(f'MSE for degree 4: {mean_squared_error(y, lr4.predict(X))}')
MSE for degree 4: 1216.1757673576178
<ipython-input-39-2eb0278d1a36>:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
X.loc[:, 'mpg^4'] = X['mpg']**4
Experimenting with complexity#
Below, a synthetic dataset is created and different complexity regression models can be controlled using the slider. Which degree complexity seems best? Consider the new data after you determine the ideal model.
from ipywidgets import interact
import ipywidgets as widgets
x = np.linspace(0, 12, 30)
y = 3*x + 15 + 4*np.sin(x) + np.random.normal(scale = 3.0, size = len(x))
# Don't Peek!
# x = np.random.choice(x, 50, replace = False)
def model_maker(n, newdata = False):
coefs = np.polyfit(x, y, n)
preds = np.polyval(coefs, x)
x_,y_,p_ = zip(*sorted(zip(x, y, preds)))
plt.scatter(x_, y_, label = 'Known Data')
plt.xlim(0, 6)
if newdata:
np.random.seed(42)
x2 = np.random.choice(np.linspace(0, 12, 1000), 35)
y2 = 3*x2 + 15 + 4*np.sin(x2) + np.random.normal(scale = 3.0, size = len(x2))
plt.scatter(x2, y2, label = 'New Data')
plt.plot(x_, p_, color = 'red')
plt.title(f'Degree {n}')
plt.legend();
interact(model_maker, n = widgets.IntSlider(start = 1, min = 1, max = len(y), step = 1));
#CHOOSE OPTIMAL COMPLEXITY
PolynomialFeatures
Scikitlearn has a transformer that will do the work of adding polynomial terms on to our dataset. For more information see the documentation here.
from sklearn.preprocessing import PolynomialFeatures
#create a little dataset (3, 2)
toy_x = np.random.normal(size = (3, 2))
toy_x
array([[0.02550067, 0.47319325],
[0.6591906 , 2.34074633],
[1.07098519, 0.09641648]])
#instantiate and transform
poly_feats = PolynomialFeatures(include_bias = False)
poly_feats.fit_transform(toy_x)
array([[2.55006681e-02, 4.73193249e-01, 6.50284073e-04, 1.20667440e-02,
2.23911851e-01],
[6.59190598e-01, 2.34074633e+00, 4.34532245e-01, 1.54299798e+00,
5.47909340e+00],
[1.07098519e+00, 9.64164790e-02, 1.14700927e+00, 1.03260621e-01,
9.29613743e-03]])
interaction_only = True
#look at the feature names
poly_feats.get_feature_names_out()
array(['x0', 'x1', 'x0^2', 'x0 x1', 'x1^2'], dtype=object)
#create a dataframe from results
pd.DataFrame(poly_feats.fit_transform(toy_x), columns = poly_feats.get_feature_names_out())
| x0 | x1 | x0^2 | x0 x1 | x1^2 | |
|---|---|---|---|---|---|
| 0 | 0.025501 | 0.473193 | 0.000650 | 0.012067 | 0.223912 |
| 1 | 0.659191 | 2.340746 | 0.434532 | 1.542998 | 5.479093 |
| 2 | 1.070985 | 0.096416 | 1.147009 | 0.103261 | 0.009296 |
Now, let’s use PolynomialFeatures to solve the earlier problem predicting hp using mpg.
#instantiate polynomial features
pfeats = PolynomialFeatures(include_bias=False)
#transform X
XT = pfeats.fit_transform(X[['mpg']])
XT.shape
(32, 2)
#examine feature names
pfeats.get_feature_names_out()
array(['mpg', 'mpg^2'], dtype=object)
#instantiate model
lr5 = LinearRegression().fit(XT, cars['hp'])
#fit, predict and score
mean_squared_error(cars['hp'], lr5.predict(XT))
1623.1102840474193
train_test_split#
To this point, we have evaluated our models using the data they were built with. If our goal is to use these models for future predictions, it would be better to understand the performance on data the model has not seen in the past. To mimic this notion of unseen data, we create a small holdout set of data to use in evaluation.
Train Data: Data to build our model with.
Test Data: Data to evaluate the model with (usually a smaller dataset than train)
Scikitlearn has a train_test_split function that will create these datasets for us. Below we load it from the model_selection module and explore its functionality. User Guide
# import function
from sklearn.model_selection import train_test_split
# create a train and test split
y = cars['hp']
X_train, X_test, y_train, y_test = train_test_split(XT, y, random_state=42)
# explore train data
X_train.shape
(24, 2)
# explore test data
X_test.shape
(8, 2)
# build model with train
lr = LinearRegression()
lr.fit(X_train, y_train)
LinearRegression()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
LinearRegression()
# evaluate train mse
train_preds = lr.predict(X_train)
print(mean_squared_error(y_train, train_preds))
1076.664148967975
# evaluate test mse
test_preds = lr.predict(X_test)
print(mean_squared_error(y_test, test_preds))
3424.62590870615
Using the test data to determine model complexity#
Now, you can use the test set to measure the performance of models with varied complexity – choosing the “best” based on the scores on the test data.
# create polynomial features for train and test
for i in range(1, 10):
poly_feats = PolynomialFeatures(degree = i, include_bias = False)
X_train_poly = poly_feats.fit_transform(X_train)
X_test_poly = poly_feats.transform(X_test)
lr = LinearRegression()
lr.fit(X_train_poly, y_train)
train_preds = lr.predict(X_train_poly)
test_preds = lr.predict(X_test_poly)
print(f'Train MSE: {mean_squared_error(y_train, train_preds)}')
print(f'Test MSE: {mean_squared_error(y_test, test_preds)}')
print('--------------------------------')
Train MSE: 1076.664148967975
Test MSE: 3424.62590870615
--------------------------------
Train MSE: 819.6896362278408
Test MSE: 2740.5076094450405
--------------------------------
Train MSE: 779.1116137946063
Test MSE: 2783.3566973521306
--------------------------------
Train MSE: 757.0893108145816
Test MSE: 3493.6718997265625
--------------------------------
Train MSE: 750.5233233919222
Test MSE: 12821.629881401424
--------------------------------
Train MSE: 757.0737985148033
Test MSE: 76165.11071392534
--------------------------------
Train MSE: 775.4900345505683
Test MSE: 450722.28290456336
--------------------------------
Train MSE: 797.4142544345755
Test MSE: 2529984.0308952453
--------------------------------
Train MSE: 814.1223225548125
Test MSE: 9191706.393489875
--------------------------------
# fit the model
# train MSE
# test MSE
Part II#
Another Example#
Returning to the credit dataset from earlier, we walk through a basic model building exercise. Along the way we will explore the OneHotEncoder and make_column_transformer to help with preparing the data for modeling. Our workflow is as follows:
Convert categorical columns to dummy encoded
Add polynomial features
Build
LinearRegressionmodel on train dataEvaluate on test data
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import make_column_transformer
# load data
url = 'https://raw.githubusercontent.com/jfkoehler/nyu_bootcamp_fa24/main/data/Credit.csv'
credit = pd.read_csv(url, index_col = 0)
# train/test split
credit.head(2)
| Income | Limit | Rating | Cards | Age | Education | Gender | Student | Married | Ethnicity | Balance | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 14.891 | 3606 | 283 | 2 | 34 | 11 | Male | No | Yes | Caucasian | 333 |
| 2 | 106.025 | 6645 | 483 | 3 | 82 | 15 | Female | Yes | Yes | Asian | 903 |
# import OneHotEncoder
ohe = OneHotEncoder(drop = 'first', sparse = False)
# instantiate
X_train, X_test, y_train, y_test = train_test_split(credit[['Ethnicity', 'Limit', 'Student']], credit['Balance'])
# fit and transform train data
XT = ohe.fit_transform(X_train)
# print(XT)
# instead we specify columns with make_column_selector
selector = make_column_transformer((OneHotEncoder(drop = 'first'), ['Ethnicity', 'Student']),
remainder = 'passthrough')
# transform train and test
XTR = selector.fit_transform(X_train)
XTS = selector.transform(X_test)
XTR
array([[0.000e+00, 0.000e+00, 0.000e+00, 7.667e+03],
[0.000e+00, 0.000e+00, 0.000e+00, 1.300e+03],
[0.000e+00, 0.000e+00, 0.000e+00, 8.550e+02],
...,
[1.000e+00, 0.000e+00, 0.000e+00, 5.673e+03],
[0.000e+00, 0.000e+00, 0.000e+00, 2.586e+03],
[0.000e+00, 0.000e+00, 0.000e+00, 1.852e+03]])
# add polynomial features
pfeats = PolynomialFeatures()
XTRP = pfeats.fit_transform(XTR)
XTRS = pfeats.transform(XTS)
# fit regression model
lr6 = LinearRegression().fit(XTRP, y_train)
# score on train
mean_squared_error(y_train, lr6.predict(XTRP))
36590.5031371065
# score on test
mean_squared_error(y_test, lr6.predict(XTRS))
44795.84838827427
A Larger Experiment#
from sklearn.datasets import make_regression
#sample data
X, y = make_regression(n_features = 4, n_samples = 1000, n_informative = 2)
data = pd.DataFrame(X, columns = ['x1', 'x2', 'x3', 'x4'])
data['y'] = y
data.head()
Now, we want to explore the effect of different complexities on the error of the model. Your goal is to explore Linear Regression model complexities of degree 1 through 15 on a train and test set of data above.
#create train and test data
#empty lists to hold train and test rmse
#loop over 15 complexities
##instantiate polynomial transformer
##transform
##instantiate regressor
##fit
##append train and test rmse
#plot model complexity vs. rmse for both train and test