Random Forests#
OBJECTIVES
Use
RandomForestClassifierto extend Decision Tree modelsCompare models in a business use case and select model that optimizes expected profit
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.pipeline import Pipeline
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.compose import make_column_transformer
from sklearn.metrics import ConfusionMatrixDisplay
from sklearn.datasets import load_breast_cancer
Ensemble of Trees#
A random forest is a meta estimator that fits a number of decision tree classifiers on various sub-samples of the dataset and uses averaging to improve the predictive accuracy and control over-fitting.
data = load_breast_cancer(as_frame = True).frame
data.head(2)
| mean radius | mean texture | mean perimeter | mean area | mean smoothness | mean compactness | mean concavity | mean concave points | mean symmetry | mean fractal dimension | ... | worst texture | worst perimeter | worst area | worst smoothness | worst compactness | worst concavity | worst concave points | worst symmetry | worst fractal dimension | target | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 17.99 | 10.38 | 122.8 | 1001.0 | 0.11840 | 0.27760 | 0.3001 | 0.14710 | 0.2419 | 0.07871 | ... | 17.33 | 184.6 | 2019.0 | 0.1622 | 0.6656 | 0.7119 | 0.2654 | 0.4601 | 0.11890 | 0 |
| 1 | 20.57 | 17.77 | 132.9 | 1326.0 | 0.08474 | 0.07864 | 0.0869 | 0.07017 | 0.1812 | 0.05667 | ... | 23.41 | 158.8 | 1956.0 | 0.1238 | 0.1866 | 0.2416 | 0.1860 | 0.2750 | 0.08902 | 0 |
2 rows × 31 columns
forest = [DecisionTreeClassifier(max_depth = 1) for i in range(10)]
X = data.iloc[:, :-1]
y = data['target']
preds = []
#loop over each tree
for tree in forest:
#sample features
X_in = X.sample(n = 5, axis = 1, )
#build tree on subset
tree.fit(X_in, y)
#make predictions
preds.append(tree.predict(X_in))
[preds[i][10] for i in range(10)]
[0, 1, 0, 1, 0, 0, 1, 1, 0, 0]
#instantiate
forest = RandomForestClassifier()
#fit
forest.fit(X, y)
RandomForestClassifier()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
RandomForestClassifier()
#predict
forest.predict(X)
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0,
0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 0, 1, 0, 0, 1, 1, 1, 1, 0, 1, 0, 0,
1, 1, 1, 1, 0, 1, 0, 0, 1, 0, 1, 0, 0, 1, 1, 1, 0, 0, 1, 0, 0, 0,
1, 1, 1, 0, 1, 1, 0, 0, 1, 1, 1, 0, 0, 1, 1, 1, 1, 0, 1, 1, 0, 1,
1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 1, 0, 0, 1, 1, 1, 0, 0, 1, 0, 1, 0,
0, 1, 0, 0, 1, 1, 0, 1, 1, 0, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1,
1, 1, 0, 1, 1, 1, 1, 0, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1, 1,
1, 0, 1, 1, 0, 0, 0, 1, 0, 1, 0, 1, 1, 1, 0, 1, 1, 0, 0, 1, 0, 0,
0, 0, 1, 0, 0, 0, 1, 0, 1, 0, 1, 1, 0, 1, 0, 0, 0, 0, 1, 1, 0, 0,
1, 1, 1, 0, 1, 1, 1, 1, 1, 0, 0, 1, 1, 0, 1, 1, 0, 0, 1, 0, 1, 1,
1, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 1, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 0, 1, 1, 0, 1, 0, 0, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 0, 0,
0, 1, 1, 1, 1, 0, 1, 0, 1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 0,
0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 1, 0, 0, 0, 1, 0, 0,
1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 0, 1, 1, 1, 0, 1, 1, 0, 0, 1, 1,
1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 0, 1, 1, 0,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 0, 0, 1, 0, 1, 1, 1, 1,
1, 0, 1, 1, 0, 1, 0, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0,
1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1,
1, 1, 1, 0, 1, 0, 1, 1, 0, 1, 1, 1, 1, 1, 0, 0, 1, 0, 1, 0, 1, 1,
1, 1, 1, 0, 1, 1, 0, 1, 0, 1, 0, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 0, 1, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 1])
Marketing Problem#
The data is related with direct marketing campaigns of a Portuguese banking institution. The marketing campaigns were based on phone calls. Often, more than one contact to the same client was required, in order to access if the product (bank term deposit) would be (‘yes’) or not (‘no’) subscribed. link
You have been tasked with finding a model for identifying further targets to offer incentive. To do so, compare a Logistic Regression and Random Forest model to select the model that maximizes expected profit using the following cost benefit information:
The cost of calling each customer is 2 dollars.
A customer who purchases the product gives a profit of 200 dollars.
Recall the expected profit is found by:
bank_marketing = pd.read_csv('https://raw.githubusercontent.com/jfkoehler/nyu_bootcamp_fa24/refs/heads/main/data/bank.csv')
---------------------------------------------------------------------------
SSLCertVerificationError Traceback (most recent call last)
File /Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/urllib/request.py:1344, in AbstractHTTPHandler.do_open(self, http_class, req, **http_conn_args)
1343 try:
-> 1344 h.request(req.get_method(), req.selector, req.data, headers,
1345 encode_chunked=req.has_header('Transfer-encoding'))
1346 except OSError as err: # timeout error
File /Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/http/client.py:1319, in HTTPConnection.request(self, method, url, body, headers, encode_chunked)
1318 """Send a complete request to the server."""
-> 1319 self._send_request(method, url, body, headers, encode_chunked)
File /Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/http/client.py:1365, in HTTPConnection._send_request(self, method, url, body, headers, encode_chunked)
1364 body = _encode(body, 'body')
-> 1365 self.endheaders(body, encode_chunked=encode_chunked)
File /Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/http/client.py:1314, in HTTPConnection.endheaders(self, message_body, encode_chunked)
1313 raise CannotSendHeader()
-> 1314 self._send_output(message_body, encode_chunked=encode_chunked)
File /Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/http/client.py:1074, in HTTPConnection._send_output(self, message_body, encode_chunked)
1073 del self._buffer[:]
-> 1074 self.send(msg)
1076 if message_body is not None:
1077
1078 # create a consistent interface to message_body
File /Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/http/client.py:1018, in HTTPConnection.send(self, data)
1017 if self.auto_open:
-> 1018 self.connect()
1019 else:
File /Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/http/client.py:1460, in HTTPSConnection.connect(self)
1458 server_hostname = self.host
-> 1460 self.sock = self._context.wrap_socket(self.sock,
1461 server_hostname=server_hostname)
File /Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/ssl.py:455, in SSLContext.wrap_socket(self, sock, server_side, do_handshake_on_connect, suppress_ragged_eofs, server_hostname, session)
449 def wrap_socket(self, sock, server_side=False,
450 do_handshake_on_connect=True,
451 suppress_ragged_eofs=True,
452 server_hostname=None, session=None):
453 # SSLSocket class handles server_hostname encoding before it calls
454 # ctx._wrap_socket()
--> 455 return self.sslsocket_class._create(
456 sock=sock,
457 server_side=server_side,
458 do_handshake_on_connect=do_handshake_on_connect,
459 suppress_ragged_eofs=suppress_ragged_eofs,
460 server_hostname=server_hostname,
461 context=self,
462 session=session
463 )
File /Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/ssl.py:1046, in SSLSocket._create(cls, sock, server_side, do_handshake_on_connect, suppress_ragged_eofs, server_hostname, context, session)
1045 raise ValueError("do_handshake_on_connect should not be specified for non-blocking sockets")
-> 1046 self.do_handshake()
1047 except (OSError, ValueError):
File /Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/ssl.py:1317, in SSLSocket.do_handshake(self, block)
1316 self.settimeout(None)
-> 1317 self._sslobj.do_handshake()
1318 finally:
SSLCertVerificationError: [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1000)
During handling of the above exception, another exception occurred:
URLError Traceback (most recent call last)
Cell In[10], line 1
----> 1 bank_marketing = pd.read_csv('https://raw.githubusercontent.com/jfkoehler/nyu_bootcamp_fa24/refs/heads/main/data/bank.csv')
File /Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/site-packages/pandas/io/parsers/readers.py:1026, in read_csv(filepath_or_buffer, sep, delimiter, header, names, index_col, usecols, dtype, engine, converters, true_values, false_values, skipinitialspace, skiprows, skipfooter, nrows, na_values, keep_default_na, na_filter, verbose, skip_blank_lines, parse_dates, infer_datetime_format, keep_date_col, date_parser, date_format, dayfirst, cache_dates, iterator, chunksize, compression, thousands, decimal, lineterminator, quotechar, quoting, doublequote, escapechar, comment, encoding, encoding_errors, dialect, on_bad_lines, delim_whitespace, low_memory, memory_map, float_precision, storage_options, dtype_backend)
1013 kwds_defaults = _refine_defaults_read(
1014 dialect,
1015 delimiter,
(...)
1022 dtype_backend=dtype_backend,
1023 )
1024 kwds.update(kwds_defaults)
-> 1026 return _read(filepath_or_buffer, kwds)
File /Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/site-packages/pandas/io/parsers/readers.py:620, in _read(filepath_or_buffer, kwds)
617 _validate_names(kwds.get("names", None))
619 # Create the parser.
--> 620 parser = TextFileReader(filepath_or_buffer, **kwds)
622 if chunksize or iterator:
623 return parser
File /Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/site-packages/pandas/io/parsers/readers.py:1620, in TextFileReader.__init__(self, f, engine, **kwds)
1617 self.options["has_index_names"] = kwds["has_index_names"]
1619 self.handles: IOHandles | None = None
-> 1620 self._engine = self._make_engine(f, self.engine)
File /Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/site-packages/pandas/io/parsers/readers.py:1880, in TextFileReader._make_engine(self, f, engine)
1878 if "b" not in mode:
1879 mode += "b"
-> 1880 self.handles = get_handle(
1881 f,
1882 mode,
1883 encoding=self.options.get("encoding", None),
1884 compression=self.options.get("compression", None),
1885 memory_map=self.options.get("memory_map", False),
1886 is_text=is_text,
1887 errors=self.options.get("encoding_errors", "strict"),
1888 storage_options=self.options.get("storage_options", None),
1889 )
1890 assert self.handles is not None
1891 f = self.handles.handle
File /Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/site-packages/pandas/io/common.py:728, in get_handle(path_or_buf, mode, encoding, compression, memory_map, is_text, errors, storage_options)
725 codecs.lookup_error(errors)
727 # open URLs
--> 728 ioargs = _get_filepath_or_buffer(
729 path_or_buf,
730 encoding=encoding,
731 compression=compression,
732 mode=mode,
733 storage_options=storage_options,
734 )
736 handle = ioargs.filepath_or_buffer
737 handles: list[BaseBuffer]
File /Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/site-packages/pandas/io/common.py:384, in _get_filepath_or_buffer(filepath_or_buffer, encoding, compression, mode, storage_options)
382 # assuming storage_options is to be interpreted as headers
383 req_info = urllib.request.Request(filepath_or_buffer, headers=storage_options)
--> 384 with urlopen(req_info) as req:
385 content_encoding = req.headers.get("Content-Encoding", None)
386 if content_encoding == "gzip":
387 # Override compression based on Content-Encoding header
File /Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/site-packages/pandas/io/common.py:289, in urlopen(*args, **kwargs)
283 """
284 Lazy-import wrapper for stdlib urlopen, as that imports a big chunk of
285 the stdlib.
286 """
287 import urllib.request
--> 289 return urllib.request.urlopen(*args, **kwargs)
File /Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/urllib/request.py:215, in urlopen(url, data, timeout, cafile, capath, cadefault, context)
213 else:
214 opener = _opener
--> 215 return opener.open(url, data, timeout)
File /Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/urllib/request.py:515, in OpenerDirector.open(self, fullurl, data, timeout)
512 req = meth(req)
514 sys.audit('urllib.Request', req.full_url, req.data, req.headers, req.get_method())
--> 515 response = self._open(req, data)
517 # post-process response
518 meth_name = protocol+"_response"
File /Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/urllib/request.py:532, in OpenerDirector._open(self, req, data)
529 return result
531 protocol = req.type
--> 532 result = self._call_chain(self.handle_open, protocol, protocol +
533 '_open', req)
534 if result:
535 return result
File /Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/urllib/request.py:492, in OpenerDirector._call_chain(self, chain, kind, meth_name, *args)
490 for handler in handlers:
491 func = getattr(handler, meth_name)
--> 492 result = func(*args)
493 if result is not None:
494 return result
File /Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/urllib/request.py:1392, in HTTPSHandler.https_open(self, req)
1391 def https_open(self, req):
-> 1392 return self.do_open(http.client.HTTPSConnection, req,
1393 context=self._context)
File /Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/urllib/request.py:1347, in AbstractHTTPHandler.do_open(self, http_class, req, **http_conn_args)
1344 h.request(req.get_method(), req.selector, req.data, headers,
1345 encode_chunked=req.has_header('Transfer-encoding'))
1346 except OSError as err: # timeout error
-> 1347 raise URLError(err)
1348 r = h.getresponse()
1349 except:
URLError: <urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1000)>
bank_marketing.head()
| age | job | marital | education | default | balance | housing | loan | contact | day_of_week | month | duration | campaign | pdays | previous | poutcome | target | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 58 | management | married | tertiary | no | 2143 | yes | no | NaN | 5 | may | 261 | 1 | -1 | 0 | NaN | no |
| 1 | 44 | technician | single | secondary | no | 29 | yes | no | NaN | 5 | may | 151 | 1 | -1 | 0 | NaN | no |
| 2 | 33 | entrepreneur | married | secondary | no | 2 | yes | yes | NaN | 5 | may | 76 | 1 | -1 | 0 | NaN | no |
| 3 | 47 | blue-collar | married | NaN | no | 1506 | yes | no | NaN | 5 | may | 92 | 1 | -1 | 0 | NaN | no |
| 4 | 33 | NaN | single | NaN | no | 1 | no | no | NaN | 5 | may | 198 | 1 | -1 | 0 | NaN | no |
bank_marketing.isna().sum()
age 0
job 288
marital 0
education 1857
default 0
balance 0
housing 0
loan 0
contact 13020
day_of_week 0
month 0
duration 0
campaign 0
pdays 0
previous 0
poutcome 36959
target 0
dtype: int64
X = bank_marketing[['age', 'balance', 'duration']]
y = bank_marketing['target']
X_train, X_test, y_train, y_test = train_test_split(X, y)
from sklearn.linear_model import LogisticRegression
lgr = LogisticRegression().fit(X_train, y_train)
forest = RandomForestClassifier().fit(X_train, y_train)
fig, ax = plt.subplots(1, 2, figsize = (20, 10))
ConfusionMatrixDisplay.from_estimator(lgr, X_test, y_test, ax = ax[0])
ConfusionMatrixDisplay.from_estimator(forest, X_test, y_test, ax = ax[1])
<sklearn.metrics._plot.confusion_matrix.ConfusionMatrixDisplay at 0x7f97c9510580>
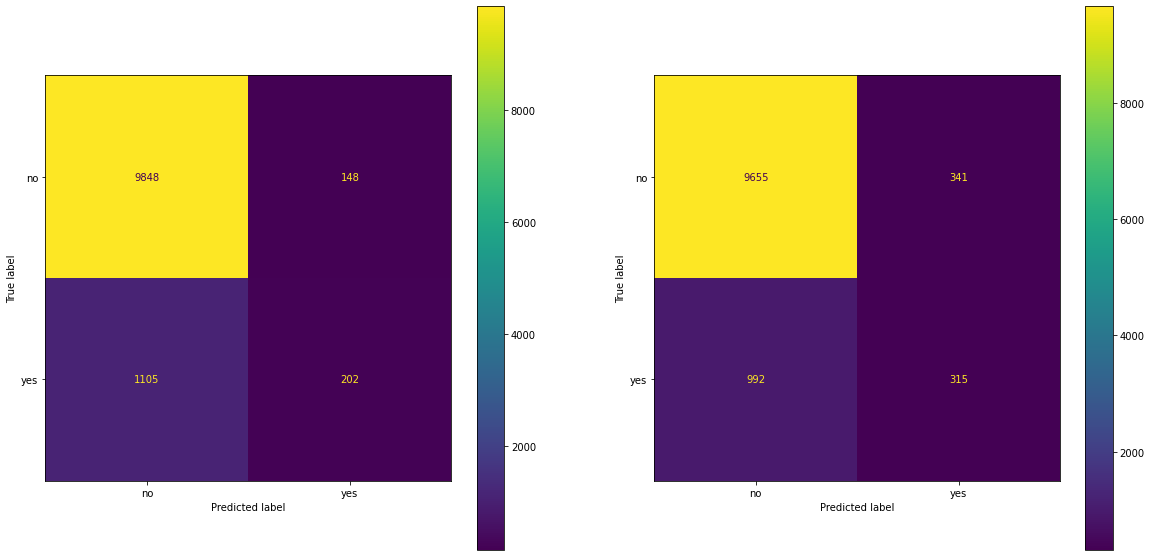
cost_benefit = np.array([[0, -2], [0, 198]])
lgr_cmat = ConfusionMatrixDisplay.from_estimator(lgr, X_test, y_test, ax = ax[0])
(lgr_cmat.confusion_matrix/lgr_cmat.confusion_matrix.sum()*cost_benefit).sum()
3.512341856144387
forest_cmat = ConfusionMatrixDisplay.from_estimator(forest, X_test, y_test)
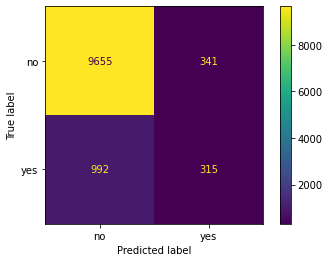
forest_cmat.confusion_matrix/forest_cmat.confusion_matrix.sum()
array([[0.854198 , 0.03016898],
[0.08776431, 0.02786871]])
(forest_cmat.confusion_matrix/forest_cmat.confusion_matrix.sum()*cost_benefit).sum()
5.457666106343449
Summary#
Please complete the form here to summarize your groups work and solutions.